
如何从零开始编写一个简单的mvc框架[0]
html解析器的原理以及实现
1. 前言
这篇文章的主要目的是为了建立一个合适的HTML解析器,在建立一个自己的mvvm框架前,通常而言对于常见的mvc框架通常都有自己的一套模板解析方法,而本文主要目的就是为了实现这一目的的基本实现。
2. HTML 是怎么被解析的?
对于HTML想必前端工程师都是十分熟悉的,html是一种简单的语言,他基于xml开发而来,最终通过一套自由的规则,对于HTML,W3C早已经规定了必要的实现方法以及定义,那么问题来了,HTML到底是怎么解析的呢?
对于html的解析,首先会想到的是在编译原理中提到的AST树,虽然作为非科班出生我的编译原理只是蹭了一节隔壁学院的基础课程,但这并不影响我去理解AST的实现,在看本文前建议对AST有一定的理解(当然不懂也是没关系的)
首先HTML的解析结果大致如下图一所示
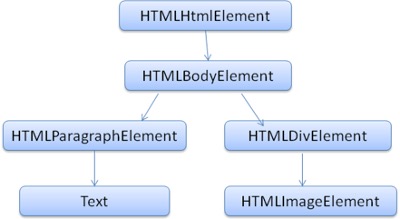
图一
而在原文中其实得出的结果是,html不能被一般的自顶向下或自底向上的解析器所解析。[1]
对此基于此,我们只能使用逐个字符逐个字符的判断,来构建语法树来完成一个基本的html构建,而在上述提及的原文中已经给出了一个不错的算法,如图二,图三所示。
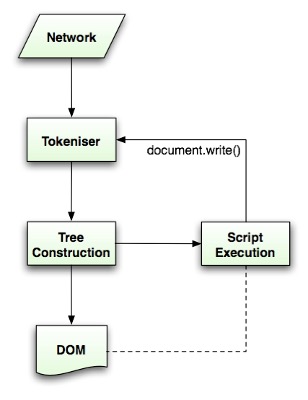
图二
![image_1bdoc055c106n1j0nhr543bvk313.png-25.5kB][https://cdn.iceprosurface.com//upload/md/2022/05/22/YvK8PI-DAKRuX.jpg]
图三
在原文中实际还提到了html是怎么被完整解析的,当然我们并不需要这么多的知识,我们仅仅需要知道怎么解析一小段html如何被解析成语法树即可。
3. 怎样编写一个HTML解析器呢?
这里我参考了一篇13年的文章,[2]在原文中介绍了如何HTML解析器是如何工作的,有兴趣的同学大可前往学习一番。
我一直秉持的是完成优先于优化,对于性能,空间什么的我们暂时不去考虑他,这样参考上述两篇文章内容,大致作出的历程应该是这样的。
3.1 预处理HTMl
首先,为了方便起见,我们并不在开头直接将 html 处理成树,并且我们规定这里我们使用的html不存在任何容错性,必须基于xhtml完整闭合。
这样首先需要一个查找器查找器的主要实现和图三是接近的,但是这一遍历器和图三存在一定的差别,首先在大部分模板中都允许html中直接携带脚本,在其中最长出现的符号之一就是<>这两个,也就是说在对于html中出现的以``{{`` 开端 ``}}``做结束,或是以 ``"`` 或 ``'``包裹的内容应当被认为是无效的的包裹符号,那么基于此,在搜搜的同时,也需要同时统计以上符号出现的次数,如果在单次tag检索中,出现的次数是偶数次,显然这个标记是有效地,否则就说明是attribute或者syntax.- 搜索tag open即
<,在找到tag open后,将开头至tag open位置的所有字符,作为 text node 压栈,同时向后查找一位如果后一位是/标记,则说明本node是一个休止符号,并记录休止。 - 寻找结束标记
>,同时将沿途所有的",',{,}符号计算次数 - 查找到>后检测次数,符合结束标记情况下,则将本段压栈,并依照记录标记写入。
- 重复此过程直到行末,或无法解析
这样我们就得到了一个具体的 html tag 栈。
接下来就是将栈解析为语法树了,(事实上这一步操作完全可以同步在上述操作中处理)
3.2 解析为dom树
现在在栈中,存在三种结构
- text node
- open tag
- close tag
现在我们依次从栈当中取出所有的内容,由于是栈所以实际上现在我们取出的内容是末尾元素,这当然是不好的,不过好在实际是js的数组可以进行队列操作,我们把它当队列来用就是了(囧)
对于模板,首先也需要以下几种类型
- 原生dom元素
- 组件元素
- 空元素(这里指的是单纯文本)
而每一个元素都会有以下属性
- 标签名
- 他们的父亲元素
- 他们的孩子元素
- 属性
- 作用域
那么对此,在所有操作前,我们首先需要创建一个组件元素也就是根元素作为载体,并将根元素设置为组件元素,同时设定当前元素为根元素,设定操作域为{}
我们首先需要取出队列头部的内容进行操作
- 创建一个数组用来储存children
- 取出元素,匹配 标签名字,将属性数组取出,设定父元素,同时从父组件记录作用域
- 将元素设定为当前操作元素
- 判断队列是否为空非空则取出新元素,如果元素是闭合标签,则说明当前元素执行结束,否则说明此个元素存在children,递归调用此方法
- 返回children数组
- 将返回的 children 数组赋值给父元素
3.3 解析属性数组
事实上我们在解析属性的时候不太可能去对属性作出非常严格的分组,这一操作更合适的阶段应该在mount阶段,这里应该做的只是简单的区分属性,在上一步中,我们应该是有提供属性的提取方法,但在这里没有实现变成数组的方法而已。
在现有的绝大部分模板引擎中,属性这一块早就使用了更加良好的方式来识别,无论是jsx的解析方式还是vue那儿的解析方法都离不开对属性的解析,而由于这些架构在属性中允许使用js表达式,这使得对属性的解析难度大大上升。
这里我们暂时不考虑需要大量进行AST分析的属性方法,我们只考虑基本的属性方法,对于最基本的属性方法,我们大可使用正则减小我们的解析压力,因为在实际使用中我们不会选择在"中使用",更多的会选择使用'
这样就带来了不少便利之处,直接用正则即可搞定了,不过
这样完整的流程就执行完毕了,下面开始编写代码。
4. 实现一个html编译器
4.1 预处理HTMl
首先我们需要一个检测输入元素的函数用来检测输入元素字符类型(只是为了更直观显示)
/**
* 检测输入的元素状态
* @param {string} el templete字符串
* @param {int} i index
* @return {int} 0代表休止标签</,1代表起始标签<,2代表标签结束符,3代表其他字符
*/
function check(el,i){
var curr = el[i]
if(curr == "<"){
if(i+1 <= el.length && i>0){
let next = el[i+1]
if(next == '\\')
return 0
}
return 1
}else if(curr == ">"){
return 2
}
return 3
}随后我们需要制作一个html解析器,将html预处理成数组
/**
* html预处理
* @param {string} html templete字符串
* @return {Array<string>} 处理数组
*/
function HTMLParser(html){
var stack = []
var start = 0
//Single quotation marks "
var sq = 0
//Double quotation marks '
var dq = 0
//Brace left {
var bl = 0
//Brace right }
var br = 0
//IsDoing Task?
var inTask = false
/**
* 初始化函数
*/
var init = function(){
inTask = false
dq = sq = bl = br = 0
}
for(let i = 0 ;i<html.length;i++){
switch(check(html,i)){
case 0,1:
// 开头是<
if(inTask){
console.error("[syntax error]on:",html.substr(0,i),",sq:",sq,",dq:",dq,",bl:",bl,",br:",br)
return stack
}else{
stack.push(html.substring(start,i))
start = i
inTask = true
}
break
case 2:
//结束符号>
if(!(sq%2) && !(dq%2) && br==bl){
stack.push(html.substring(start,i+1))
start = i+1
init()
}
break
case 3:
// 其他符号累计计数器
switch (html[i]) {
case "'":
sq += 1
break
case '"':
dq += 1
break
case '{':
bl += 1
break
case '}':
br += 1
break
}
}
}
return stack
}让我们看看运行结果如何?
var templete = `
<div class="contacts-wrap flex">
<div class="contacts-panel" v-for="x>=3">
<a :href='contact.url' class="flex">
<div class="contacts-number">
<div class="detailed">{{contact.title}}</div>
<div class="()=>{return function(){cc}}">{{contact.num}}</div>
</div>
<div class="contacts-icon">
<img :src="contact.img">
</div>
</a>
</div>
</div>
<div class="panel-title">实时动态</div>
<div class="statistics-wrap flex">
<div class="statistics-option" v-for="item in statistics">
<div class="statistics-detailed">{{item.title}}</div>
<div class="statistics-number">{{item.count}}</div>
<a :href="item.url">立即查看</a>
</div>
</div>
`
console.log(HTMLParser(templete))结果:
["
", "<div class=\"contacts-wrap flex\">", "
", "<div class=\"contacts-panel\" v-for=\"x>=3\">", "
", "<a :href='contact.url' class=\"flex\">", "
", "<div class=\"contacts-number\">", "
", "<div class=\"detailed\">", "{{contact.title}}", "</div>", "
", "<div class=\"()=>{return function(){cc}}\">", "{{contact.num}}", "</div>", "
", "</div>", "
", "<div class=\"contacts-icon\">", "
", "<img :src=\"contact.img\">", "
", "</div>", "
", "</a>", "
", "</div>", "
", "</div>", "
", "<div class=\"panel-title\">", "实时动态", "</div>", "
", "<div class=\"statistics-wrap flex\">", "
", "<div class=\"statistics-option\" v-for=\"item in statistics\">", "
", "<div class=\"statistics-detailed\">", "{{item.title}}", "</div>", "
", "<div class=\"statistics-number\">", "{{item.count}}", "</div>", "
", "<a :href=\"item.url\">", "立即查看", "</a>", "
", "</div>", "
", "</div>"]
4.2 解析为dom树
首先我们需要定义element类来放置各种dom
class element {
constructor(tag,prop,parent,scope){
this.tag = tag
this.prop = prop
this.parent = parent
this.scope = scope
this.children = []
}
addChild(ele){
this.children.push(ele)
}
}
首先需要写个主要方法,用来解析根节点,随后使用一个递归方法依次解析dom元素,随后返回给根节点,虽然按照逻辑是先写根节点的,但是递归自下而上写要比自顶而下要容易不少
首先拟定基本结构
function ElementParser(el,parent,stack,scope){
// 创建一个元素
while(stack.length > 0){
// 取出元素
if([].indexOf(name) != -1){
// 保留的可能会用于tag过滤的地方
}else if(tag){
switch(/*检测node类型这和上面的方法一致*/){
case 0:
// close tag,如果closename和tag不符,则报错返回false
break
case 1:
// 说明有child 递归获取ElementParser(tag,ele,stack,scope)
// 判断child是不是false如果是说明语法错误,也递归向上返回false即可
break
case 3:
//文字节点直接写入即可
break
}
}
}
// 如果这里都出现了,显然解析到末尾了,说明这个domclose标签有问题
return false
}
然后这样看来我们需要一个解析tag 属性和name的方法,以及一个解析close tag的方法
先写好这两个方法
/**
* 将tag解析为合适的数据格式
* @param {string} el templete字符串
* @return {string} name tag name
* @return {string} props 属性字符串,这在将来在做处理
*/
function TagParser(el){
// 第一个开始到第一个空格显然是 tagname
var name = el.substring(1,el.indexOf(" "))
// 第一个空格开始到最后一个>位置显然是全部的props
// TODO: 这里应该改进为属性数组
var props = el.substring(el.indexOf(" ")+1,el.lastIndexOf(">"))
return {name,props}
}
/**
* 检测输入的元素状态
* @param {string} node templete字符串
* @return {int} 0代表结束标签,1代表起始标签,3代表其他字符
*/
function CloseTagParser(el){
return el.substring(el.indexOf("/")+1,el.lastIndexOf(">"))
}
最后我们吧elementparser这个方法写完
function ElementParser(el,parent,stack,scope){
var {name,props} = TagParser(el)
var ele = new element(name,props,parent);
while(stack.length > 0){
var tag = stack.shift().trim()
if([].indexOf(name) != -1){
}else if(tag){
switch(checkNode(tag)){
case 0:
var closeTag = CloseTagParser(tag)
if(closeTag!=name){
console.error("[syntax error]expect tag:",name,",but found:",closeTag,".in \n",el)
return false
}else{
return ele
}
break
case 1:
var child = ElementParser(tag,ele,stack,scope)
if(!child) return false
ele.addChild(child)
break
case 3:
ele.addChild(new element("text",[],parent,scope))
break
}
}
}
console.error("[syntax error]expect tag:",name,",but not found. in \n",el)
return false
}照这个写个单层结构基本就是root节点了
function HTMLCompnonentParser(componentName,scope,stack,parent){
var root = new element(componentName,[],parent,scope);
while(stack.length > 0){
var tag = stack.shift().trim()
if(tag){
switch(checkNode(tag)){
case 0:
// root ele 必然没有close tag 如果出现说明出错
var closeTag = CloseTagParser(tag)
console.error("[syntax error]unexpect close tag:",closeTag,".")
break
case 1:
var child = ElementParser(tag,root,stack,scope)
if(!child) return false
root.addChild(child)
break
case 3:
root.addChild(new element("text",[],parent))
break
}
}
}
return root
}
4.3 解析属性数组
/**
* 将tag解析为合适的数据格式
* @param {string} el templete字符串
* @return {string} name tag name
* @return {string} props 属性字符串,这在将来在做处理
*/
function TagParser(el){
// 第一个开始到第一个空格显然是 tagname
var name = el.substring(1,el.indexOf(" "))
// 第一个空格开始到最后一个>位置显然是全部的props
var props = []
var propstr = el.substring(el.indexOf(" ")+1,el.lastIndexOf(">"))
// 针对所有成对出现元素
var regProp = /([:\@]?\w[\w-]*\=\"[^\"]*?\")|(([:\@]?\w[\w-]*\=\'[^\']*?\'))/g
// 针对所有单项元素
var regSingle = /(\s\w+(?=\s+|$))/g
var matchs = propstr.match(regProp)
// 这里是可以直接在用一次正则获取的,但算了算还要拼装还是直接用map吧
if(matchs) props = props.concat(matchs.map((r)=>{
var result = [r.substring(0,r.indexOf('=')),r.substring(r.indexOf('=')+1,r.length)]
result[1] = result[1].substring(1,result[1].length-1)
return {key:result[0],value:result[1]}
}))
matchs = propstr.match(regSingle)
if(matchs) props = props.concat(matchs.map((r)=>{
return {key:r.trim(),value:true}
}))
return {name,props}
}
就这样稍稍魔改一下即可这样我们就获得一个简化版的dom树了,在之后的所有模板操作实际都是对这里面这颗树的内容作出修改,然后使用一套特殊的diff方法计算差异后渲染到页面上,当然咯这里的方法还是少一个遍历方法,也没有封装成一个组件,这在后面都会逐步增加的!
在后面会慢慢补全在github上面的实例代码,期待下一篇对于模板渲染的文章吧!
雄领IT,浏览器工作原理(四):HTML解析器(HTML Parser),http://blog.csdn.net/lxcao/article/details/52860746?ref=myread ,2016-10-19. ↩︎
xuesong123, html解析器工作原理.http://blog.csdn.net/xuesong123/article/details/8637159 ,2013-03-05. ↩︎
本文标题:如何从零开始编写一个简单的mvc框架[0]
本文链接:https://iceprosurface.com/2017/04/15/2017/2017-04-15-how-to-implement-a-simple-mvc/index.html
作者授权:除特别说明外,本文由 icepro 原创编译并授权刊载发布。
版权声明:本文使用「署名-非商业性使用-相同方式共享 4.0 国际」创作共享协议,转载或使用请遵守署名协议。
